
前言
词云,也称为文字云或标签云,是一种将文本中出现频率较高的关键词以视觉化的方式展现的图形。词云的文字大小、颜色、形状等都可以根据不同的需求进行调整,以突出文本的主旨或者传达一定的情感。词云可以用于分析文本的内容,展示关键词的热度,美化文本的呈现,增加文本的趣味性等。
词云的制作方法有很多,有些是在线的,有些是需要下载相关软件的。本次实验主要通过使用 WordCloud 库在 Python 中绘制中文词云,使用的 IDE 为 Jupyter。
准备工作
在本次实验前,我们需要提前准备以下素材:
使用的库文件
wordcloud(词云制作)jieba(中文分词)numpy(数据处理)matplotlib(基础画图)PIL(读取图片)
如果没有以上相关库,可使用 pip 或者 conda 进行安装,建议使用国内镜像。
实验原理
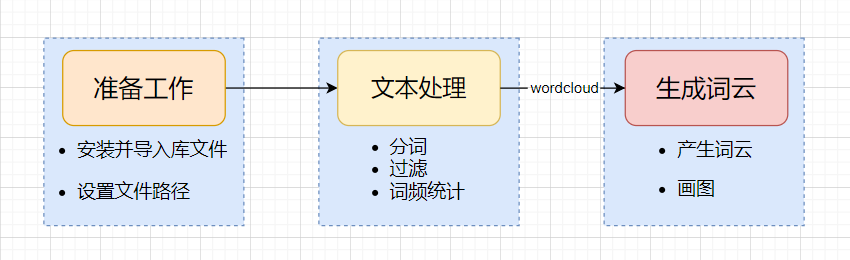
在完成上述的准备工作后,就需要对我们已有的文本进行处理,因为生成词云 wordcloud 默认会以空格或标点为分隔符对目标文本进行分词处理。对于中文文本,分词处理需要由用户来完成。一般步骤是先将文本分词处理,然后以空格拼接,再调用 wordcloud 库函数。
最后便是生成词云图片,wordcloud 库的核心是 WordCloud类,所有的功能都封装在其中。使用时需要实例化 一 WordColoud类 的对象,并调用其 generate(text) 方法将 text 文本转化为词云。
程序设计
1. 引入相关库文件并设置文件各径
库文件的引入:
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import jieba文件路径的设置:
path_text = 'D:/tempRes/texts/2022政府工作报告.txt'
path_stop = 'D:/tempRes/stopwords/hit_stopwords.txt'
path_mask = 'D:/tempRes/mask/ChinaMap.png'
path_font = 'D:/tempRes/fonts/msyh.ttc'这里建议放在同一文件夹目录下,文件后缀名保持一致。对于字体的话需要展现什么字体就把该 字体路径 + 后缀名 写上即可,本次实验采用的是 Win10 自带的微软雅黑,具体操作方法在准备工作中。

2. 文本处理
根据上述原理图,我们将程序分为3个部分。在准备工作完成后,便要对文本进行处理。我们需要读取一篇文章通过停用词表统计它的词频并表生成一个“词频表”,然后生成一个字典(dict)保存。
首先,读取一篇文章以及停用词表并通过 split() 将字符串分割成一系列字符串。这里 STOPWORDS_CH 返回的是一个列表(list)。
text = open(path_text, encoding='utf8').read()
STOPWORDS_CH = open(path_stop, encoding='utf8').read().split() 通过 jieba.cut() 对读取到的 text 分割成一个个词或词组,对里面的每一个词过滤掉没有意义的“停用词”,最后保留长度大于1的词组(len(w) > 1)。
word_list = [
w for w in jieba.cut(text)
if w not in STOPWORDS_CH and len(w) > 1
]
freq = count_frequencies(word_list) 然后对获取到的 word_list 进行词频统计,下面将它封装成了一个函数:
def count_frequencies(word_list):
freq = dict()
for w in word_list:
if w not in freq.keys():
freq[w] = 1
else:
freq[w] += 1
return freq
freq = count_frequencies(word_list)3. 生成词云
在生成词云之前我们需要先了解一下 wordcloud 库核心 WordCloud类 中的常用参数以及常用方法。
WordCloud 对象常用参数:
| 参数 | 说明 |
|---|---|
| font_path | 设置字体,指定字体文件的路径 |
| width | 图片宽度,默认 400 像素 |
| height | 图片高度,默认 200 像素 |
| mask | 词云形状,默认为矩形 |
| min_font_size | 词云中最小的字体字号,默认 4 号 |
| font_step | 字号步进间隔,默认 1 |
| max_font_size | 词云中最大的字体字号,默认根据高度自动调节 |
| max_word | 词云显示的最大词数,默认 200 |
| stopword | 设置停用词(需要屏蔽的词),停用词不在词云中显示,默认使用内置的STOPWORDS |
| background_color | 图片背景颜色,默认黑色 |
WordCloud 常用方法:
| 方法 | 功能 |
|---|---|
| generate(text) | 加载词云文本 |
| to_file(filename) | 输出词云文件 |
了解以上参数后,便可开始制作自己想要中文词云。我们需对图片转换为numpy类型数组,然后建立一个词云对象(wcd)以便我们后面生成图片及查看。
# 图片处理
im_mask = np.array(Image.open(path_mask))
wcd = WordCloud(font_path=path_font,width = 1000, height = 700,
background_color='white',max_words=200, max_font_size=150,
mode="RGBA",
colormap="Reds",
mask=im_mask,
)
wcd.generate_from_frequencies(freq) 在这里我除了设置以上 WordCloud 中参数外,还额外添加了 colormap 配色集,需要注意和提供的参数一致!可根据喜好设定,在这里使用的是红色。
在这里就词云已经生成,以下代码是如何查看以及保存和对比:
ax = plt_imshow(wcd)
ax.figure.savefig(f'2022政府工作报告_wcd.png', bbox_inches='tight', dpi=150)
fig, axs = plt.subplots(1, 2)
plt_imshow(im_mask, axs[0], show=False)
plt_imshow(wcd, axs[1])
fig.savefig(f'2022政府工作报告.png', bbox_inches='tight', dpi=150)4. 运行结果
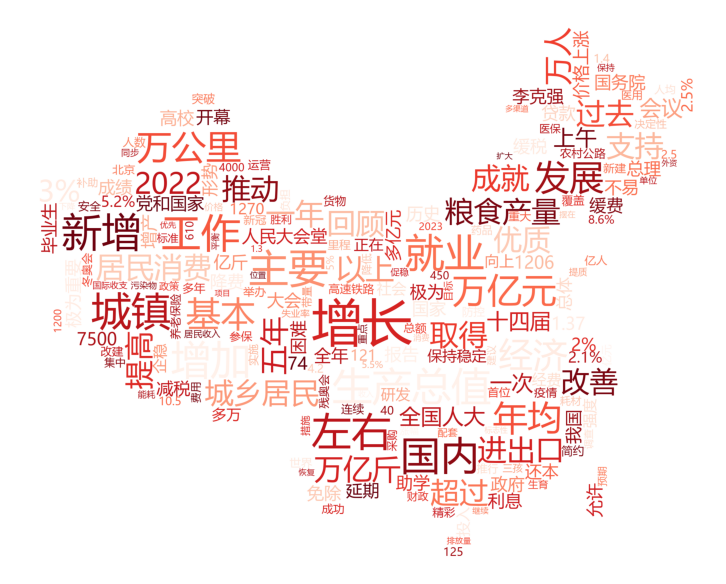
示例 1:
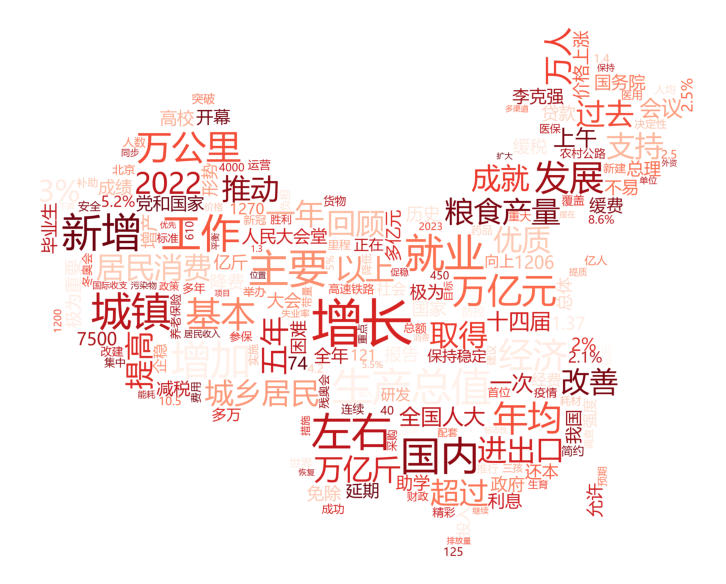
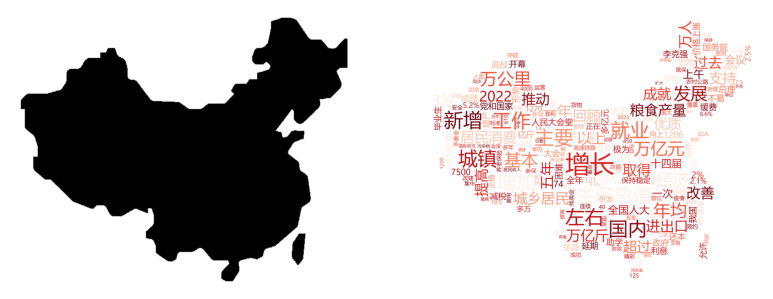
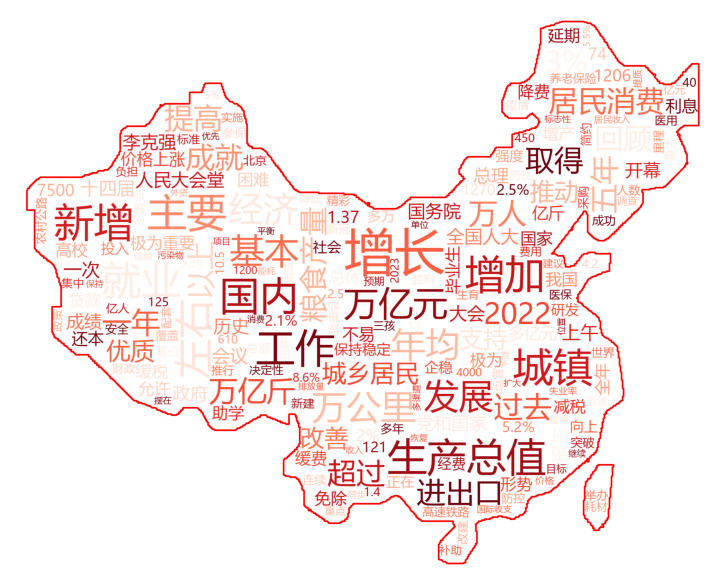
示例 2:
这个加上了红色轮廓,只需在
WordCloud中加上轮廓宽度(contour_width)和轮廓颜色(contour_color)即可,不要和mode同用。
参考文献
至此,本次实验结束,大力感谢文章中提及的作者对我本次学习的帮助!若因此对原作者造成侵权,烦请原作者留言告知,我会立刻删除相关内容。最后代码放在我的Github中。



哇 真不错
很棒,希望能用上
做大做强!
牛皮!